一、浏览器怎么解析出DOM
浏览器请求阶段
浏览器向服务器发起http请求,经过TCP/IP三次握手确认链接后,服务器将需要的代码发回给浏览器,这里我们只说返回的是html文件,其他的不多赘述。
解析dom树阶段
浏览器首先将收到的html代码,通过html解析器解析构建为一颗DOM树。数据结构中有许多的树。
根据css渲染DOM树阶段
浏览器按从上到下,从左到右的顺序,读取DOM树的文档节点,顺序存放到一条树状结构上。而每一个DIV就是节点,这棵树就是文档流。当我们我们读取到的节点是属于另一个节点下的子节点,那么我们放到树上的位置就是该节点盒子的内部。
如果子节点下还有子节点,在树状结构中继续套盒子内部。根据它在DOM树上的结构,可以嵌套的层级没有限制的哦。
文档流排完之后,根据div上的class或者id等取对应的css资源(也是从http请求中获取到的)source中找到对应的css样式属性,将对应的属性绑定到盒子上,就完成过了文档树。
浏览器渲染阶段
布局完成之后,我们在页面上其实是看不到任何内容的
浏览器只是计算出了每一个节点对象应该被放到页面的哪个位置上,但并没有可视化。
因此最后一步就是将所有内容绘制出来,完成整个页面的渲染。
二、虚拟dom树原理
虚拟DOM自然就是跟DOM有很大关系的了。我们在使用原生JS开发或者使用Jquery开发,经常就会操作DOM,但是我们使用的时候发现,每次我们改变DOM的时候,页面再次渲染,会消耗很多性能,有些时候会占到70%左右的渲染性能。如果我们尽可能减少dom树的操作或者在上文中提到的减少dom流中的改变,这样就会有效的提高浏览器的渲染速度。这样就有了虚拟dom的理论。
实际在React中,会把DOM转换成JavaScript对象,然后再把JavaScript对象转化成DOM,这样我们对于DOM的操作,实际上是在操作这个JavaScript对象。
虚拟的DOM的核心思想是:对复杂的文档DOM结构,提供一种方便的工具,进行最小化地DOM操作。
构建虚拟DOM
例子:
import React from 'react';
import ReactDOM from 'react-dom';
let element = React.createElement("h1", {
id: "test",
className: "testClass"
}, "test");
ReactDOM.render(element, document.getElementById('root'));分析一下上面的代码:React.createElement() 方法传入了3个参数: 第1个参数对应的是标签(tag)名称,第2个参数是属性(id,class,attr…),第三个参数是内容(text),然后返回某个值。ReactDOM.render()方法接收了两个参数,第一个参数是刚刚提到的某个值,第二个参数是获取到的root元素,对应的是index.html中的<div id="root"></div>
在上面的代码中加入console.log(element),打印出element的值,如下: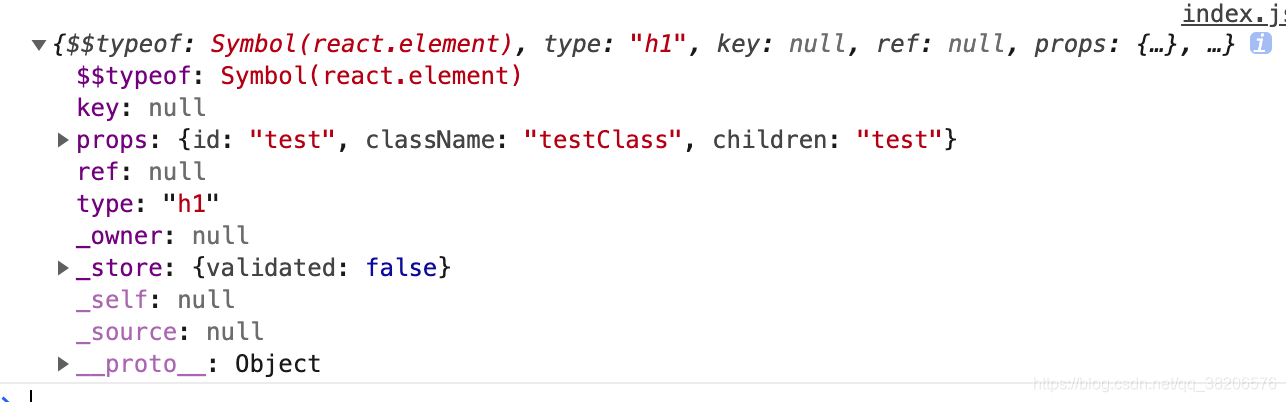
上面的console吐出的是一段dom数据,此时React.createElement()方法创建了虚拟DOM。
模拟实现React.createElement()
有上图可以这个对象有多个属性,目前来说对我们比较重要的是props和type属性,所以先实现对于这两个属性的操作。React.createElement() 接收3个参数,现在要把这3个参数合并到type和props中。React.createElement() 接收3个以上参数,说明该元素里面有多个子元素(这些子元素仍然是React.createElement()),那么把第二个参数后面的所有参数转换成数组放入children中
function ReactElement(type, props) {
const element = { type, props };
return element;
}
function createElement(type, config = {}, children) {
let propName;
const props = {}; // 定义props
for(propName in config) {
props[propName] = config[propName]; // 复制config的属性到props中
}
// 处理children
const childrenLength = arguments.length - 2;
if(childrenLength === 1) {
props.children = children;
} else {
// 有多个子元素的情况
props.children = Array.from(arguments).slice(2);
}
return ReactElement(type, props);
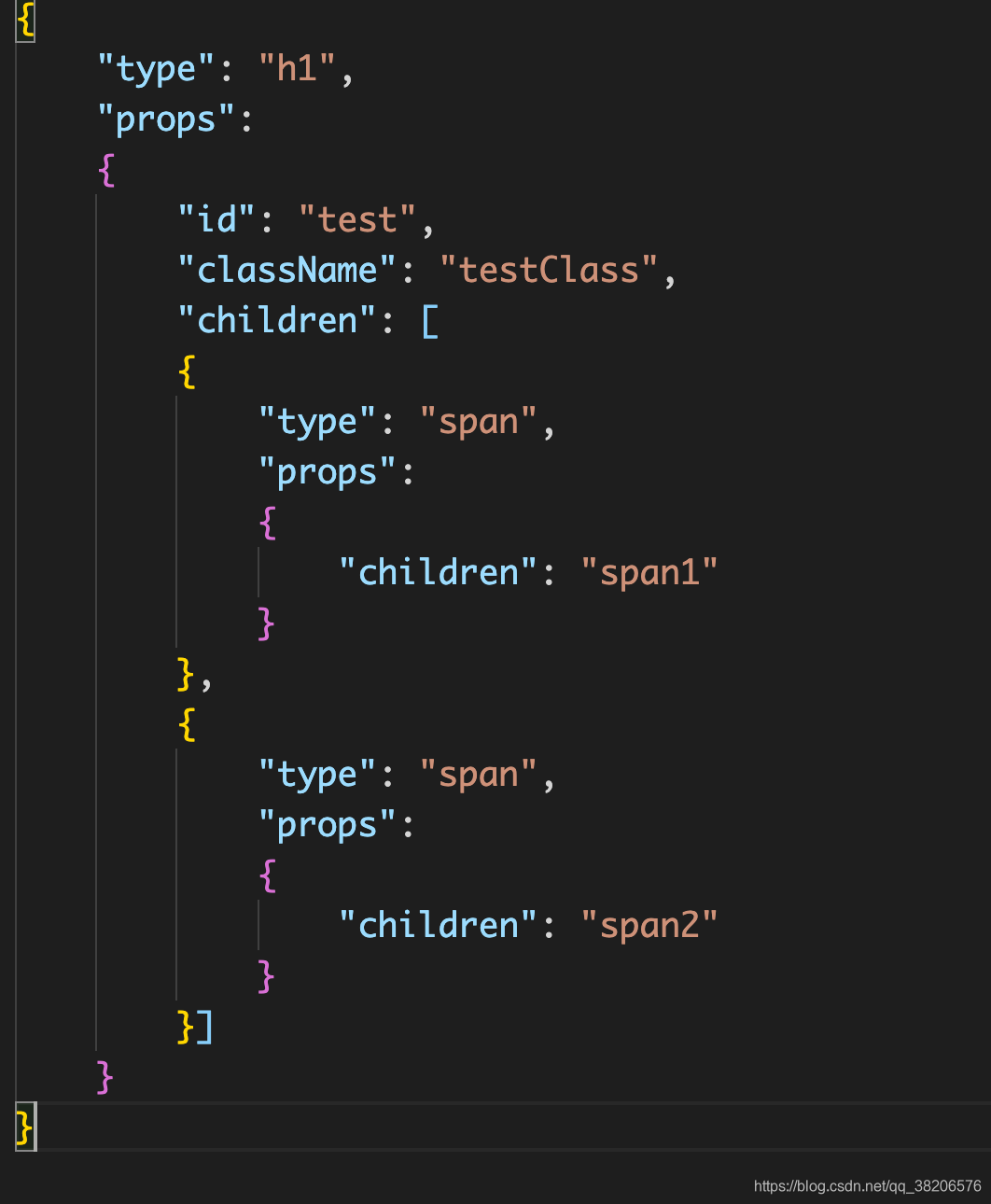
}test code :
const element = createElement("h1", {
id: "test",
className: "testClass"
}, createElement("span", null, "span1"), createElement("span", null, "span2"));
console.log(JSON.stringify(element))console结果(实际是一个javascript的对象):
React Diff算法
两个相同的组件产生相似的DOM结构,而不同的组件产生不同的DOM结构。
对于同一级别的一组子节点,可以通过唯一的ID来区分它们。
算法上的优化是 React 整个界面 Render 的基础,保证了整体界面渲染的性能。
为了在树之间进行比较,我们首先要能够比较两个节点,在 React 中即比较两个虚拟 DOM 节点,当两个节点不同时,应该如何处理。这分为两种情况:
- (1)节点类型不同
- (2)节点类型相同,但是属性不同。
节点类型不同:直接删除原节点, 插入新节点。
React 的 DOM Diff 算法实际上只会对树进行逐层比较,两棵树只会对同一层次的节点进行比较如下所述。
当我们调用 setState 时,state 内部状态发生变动,再次调用 render 方法就会生成一个新的虚拟 DOM 树,这样我们就能使用 diff 方法计算出新老虚拟 DOM 发送变化的部分,最后使用 patch 方法,将变动渲染到视图中。
它是比较新旧VDOM的更改,然后将更改的部分更新到视图。 对应于代码,它是一个diff函数,返回一个补丁。
总结
1.虚拟DOM基本上不会引发页面布局和重绘操作。
2.在频繁修改虚拟DOM之后(以及在setState之后),一次比较并修改需要在真实DOM中修改的部分,最后在真实DOM中排版和重绘以减少布局和重绘的损失。
3.虚拟DOM有效地减少了大量(真实DOM节点)的重绘和排版,最终的差异与真实DOM进行了比较,并且只渲染一修改的那一小部分(与2相同)
使用虚拟DOM的损耗计算:
总损耗 = 虚拟DOM增删改 + (与Diff算法效率有关)真实DOM差异增删改 + (较少的节点)排版与重绘
直接使用真实DOM的损耗计算:
总损耗 = 真实DOM完全增删改 + (可能较多的节点)排版与重绘
简而言之,为了减少因频繁进行大面积重绘而导致的性能问题,不同的框架不一定需要虚拟DOM。 关键是要查看框架是否经常触发大面积DOM操作。



